
The 6 key AI variables to watch
Your cheat sheet for getting up to speed on high-level AI trends

It often feels like developments in artificial intelligence move so quickly that even many in the industry struggle to keep up. How do we know what are real breakthroughs and what is hype? For something that might impact so many of our livelihoods in such a profound way, how do the rest of us know what to pay attention to?
Writing this piece has been a exercise in helping me better contextualize breaking news from the field, and think about what the impact of today’s technology might be on the far future. After reading, hopefully you’ll have a good enough level of interactional expertise to be able to make sense of the excellent work of the many writers and researchers I’ve cited here, and potentially get ready do some work in the field yourself.
About my own background: I have a B.A. in economics and 10+ years in public service, mostly in technology-related operations. I am not a specialist in AI, but rather someone who is generally interested in making sense of various predictions about the future. In my past 2 years of writing this newsletter, I’ve done a deep dive into how we got to a 40 hour workweek and where we go from here, including a base case and an aggressive prediction about what that might look like in the year 2120. I’ve also explored how the nature of work has changed over time, and plan to do some more specific predictions of this as well. Some key questions I’ll be asking myself include how transformative AI and robotics will be compared to the impact of mechanized agriculture, and if employment in any other fields might be curiously stable in spite of new technology, like construction has been since 1910.
Substack estimates this is about a 70-minute read, but there are some high level summaries at the top for you to go directly to the parts you might be most interested in. Over the course of this piece, I’ve referenced over 300 different articles from over 100 unique sources, so if you read my summary and dive into some of the linked pieces, you should give yourself credit for reading a book!
Without further ado, here are the 6 key AI variables to watch:
Computing power and price: the scale of this is already massive and steadily growing as per Moore’s Law, but there is only one more order of magnitude of conventional growth left before hitting some hard physical limits in the 2030s. Price-performance gains have slowed and might slow further as these limits are approached.
Model size: the size of AI models grew rapidly around 2020, but could hit some limits (at least for high-quality text) as early as 2024. Image, video, and other models may continue to grow into the 30s and 40s, but inference costs, slower progress in memory bandwidth, and difficulty scaling the allowable size of prompts are important constraints that might limit growth to just two orders of magnitude over the next decade.
Accuracy and alignment: AI advances past human ability in many areas, but has appeared to level out below human ability in others. There are many benchmarks for evaluating performance, and just as many debates about the validity of those benchmarks. The challenges of measuring the safety of self-driving cars is an instructive example, and there is a lot we can learn from prediction markets on how we can better visualize progress and mitigate potential harms.
Algorithmic efficiency: like the quality of software in general, this is hard to measure. However, we’ve seen significant advances in many areas here, including making more efficient use of data and parameters, better techniques for fine-tuning, the development of interpretability features, interactions across different modes (e.g. text vs. image), and human skill at using AI. Whether the improvements here are easily reproducible in the open source world or not will have significant impacts on how AI develops going forward.
Investment: the scale of money invested in both AI hardware and software has been increasing rapidly, eclipsing spending on robotics, though there is a wide range of uncertainty in these predictions. As of October 2023, the stock market appears to have priced in 2% more annual growth than usual over the next 10 years.
Public opinion and regulation: these aspects touch all other variables in some way, and accountability, ownership, and agency are important concepts in law. Where automated decision-making could be highly consequential, regulation is likely. Public opinion and trust in AI tends to be lower in Western countries and higher elsewhere with some exceptions and caveats, though worries about jobs and the economy are significant everywhere, and risks posed by AI are difficult to weigh against each other. To stay informed about trends related to regulation, privacy advocates have created comprehensive legislation trackers across all levels of government.
The bottom line: transformative AI that could automate a significant amount of work is possible within the next decade, but the reality is likely to be more complex. Better understanding accuracy and alignment is important, and what I intend to focus on next.
** Note that this is a living post. I intend to update it as significant breakthroughs happen. Where there’s uncertainty among experts, I’ve tried to explain as concisely as I can, but please comment if there’s anything you think I’ve gotten wrong.
Please do bookmark, subscribe, and share if you’ve found this guide useful!
1. Computing power and price
Computers, and the artificial intelligence they enable keep getting more powerful. From beating the best human chess players as early as the 1990s to embedding themselves into countless aspects of daily life in the the 2010s to passing business school exams and Amazon coding interview questions in the 2020s, it’s left many wondering when machines might surpass most or all of our human abilities. Some forecasters have based their predictions on a mechanistic comparison between the computing power of computers and that of the human brain (often referred to as “biological anchors”). But what do the large numbers of FLOP/s in predictions like these mean?
How to measure and predict the power of computers?
The power of a computer is typically measured in the number of floating point operations per second (FLOP/s) it can perform. For example:
The best individual computers (based on GPU performance1) in 2023 perform in the teraFLOP/s range (1e12-14, or trillions or FLOP) in 2023. These surpass the very best supercomputers from around the year 2000.
Hundreds or thousands of individual GPUs can be parallelized together to make supercomputers in the petaFLOP/s range (1e15-17, or quadrillions of FLOP).
Tens and hundreds of thousands of individual GPUs can be put together to make world’s current fastest supercomputers, in the ExaFLOP/s range (1e18+, or quintillions of FLOP).
So, will our individual computers one day be as powerful as today’s supercomputers? According to Moore’s Law, which has held relatively steadily since the 1960s, if computing power doubles every two years (or 10x every 6½ years), we could get there between 2049 and 2062. However, there are a few other factors to consider.
The limits to Moore’s Law
On a price-performance basis, progress since ~2013 has been slightly slower than what Moore’s Law would predict. While the number of transistors continues to increase, the price per transistor has stagnated, so price-performance improvements are limited to other factors, like the number of logical cores.
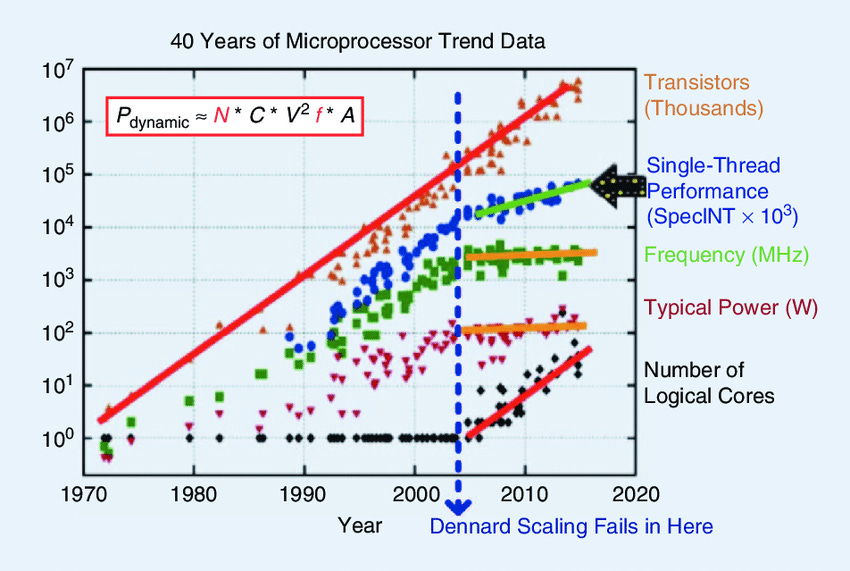
On the other hand, the computing power of the largest supercomputers continues to grow slightly faster than Moore’s law, growing by an order of magnitude in just 5 years thanks to increased investment.
However, this rate of growth could also change as we approach some possible absolute limits. Sometime in the 2030s, the size of transistors may approach the size of individual atoms.
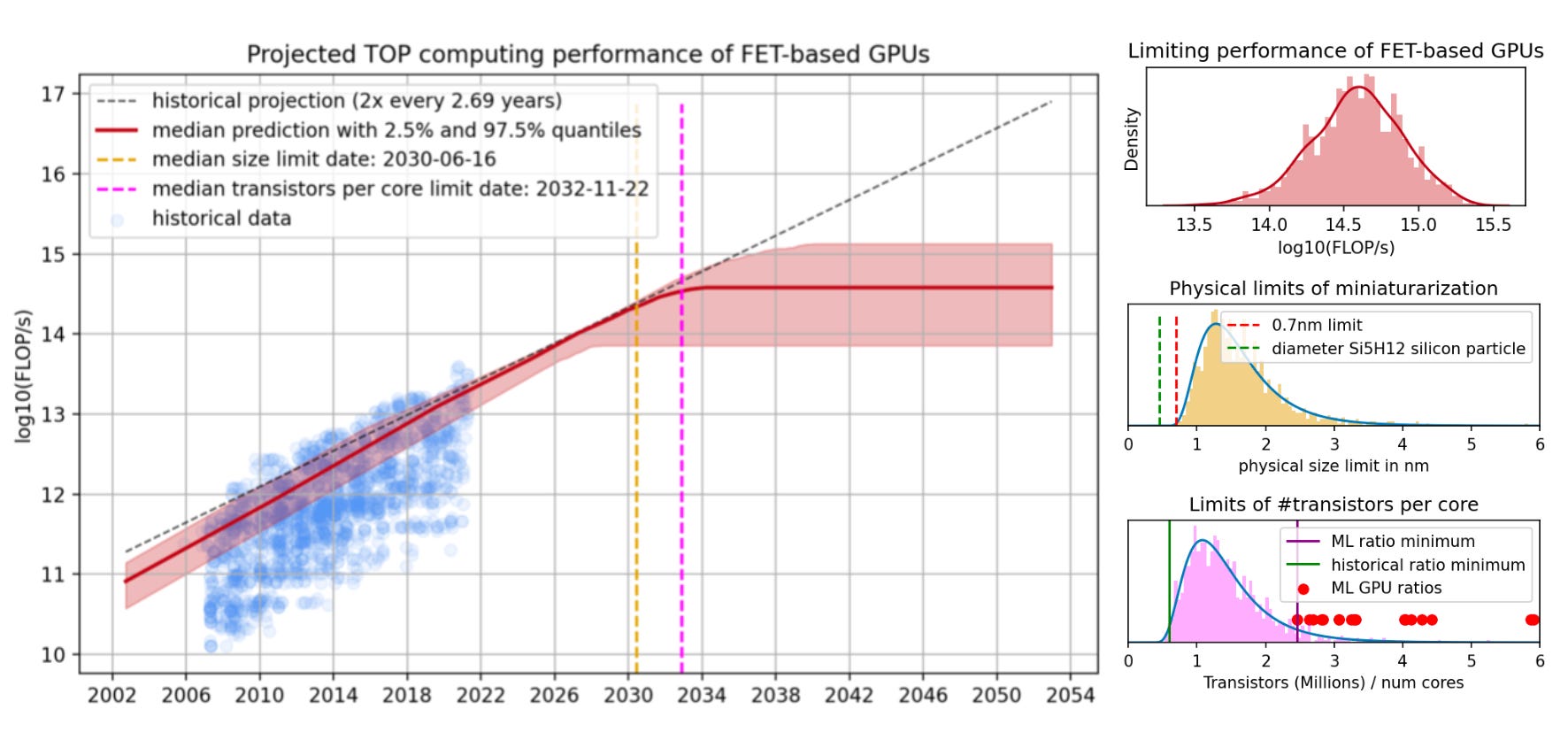
This means that we might only ever see individual processors that are only about 10 times as powerful as today’s. But if AI models trained on supercomputers continue to have many practical applications, and scaling them up continues to provide value, we could see ever more powerful and expensive machines, thousands of times faster2 than current ones. And if we see more practical breakthroughs in quantum (which some are skeptical of) or neuromorphic computing, entirely new paradigms3 will be opened up.
But what is done with all of this computing power?
2. Model size
If the 2010s were the decade of big data, the 2020s have been the decade where enormous amounts of data have been fed into the neural networks that power Large Language Models (LLMs) like ChatGPT, as well as others trained on images, video, and other modalities. The initial step of pre-training a model results in the creation of a foundation model, which can later be fined-tuned. While these tools can sometimes seem magical, at a high level, they are generally just predicting the next most logical word (or pixel, etc.) based on the statistical associations present in their data.
The large amount of data, and associations between each data point— in other words, the size of these machine learning models— is staggering: if you thought an exaFLOP was big, just imagine running an exaFLOP computer for about 10 million seconds (116 days). 1e18 FLOP/s times 1e7 seconds brings us up to 1e25 FLOP (minus some loss), or about half the size of GPT-4, the world’s largest LLM behind ChatGPT’s “premium” tier as of September 2023. That’s similar to the number of individual molecules in a quarter cup of water, which I think is a helpful way to think of the size of these models as they continue to get bigger4.
What makes AI models so big?
It’s helpful to think of the power required to train a foundation model as a function of two dimensions, tokens and parameters.
The number of tokens and parameters are relevant for determining the cost of two other fundamental aspects of training and using AI models: the forward pass, inference, and the context window. More detailed definitions of each of these terms are below:
Tokens
This is just the quantity of data that a model is trained on. For language models, there are about 1.3 tokens per word. The Common Crawl, which scrapes about 10% of the entire public internet, consisted of about 1.4 trillion tokens in 2019. GPT-4 is estimated to have been trained on about 10x this number, or about 100,000x the total number of words a child encounters by age 10.
Parameters
Each token has a number of weights associated with it to help it figure out what word it should output next. These weights are called parameters, and best practice as of 2023 (based on the results of the frequently-cited “Chinchilla paper”) suggests the use of one parameter per roughly 20 tokens.
Forward pass
Every time a model is queried, an operation known as a “forward pass” is performed to predict the next token that will be output as your response, based on the values of its parameters. During training, the parameters associated with each token are constantly being updated, making each forward pass very large. Furthermore, 6 forward passes are required during training to query all of the data in the model and perform the update (a process known as backpropagation), so the total “size” of the model is the number of tokens x the number of parameters x 6.
Inference and the context window
A simple query of the model after training has been completed is called inference, and it is much less computationally expensive than training. While it still is based on the number of parameters, it is only multiplied by the number of tokens in the “context window” (e.g. how many words are in the question you asked ChatGPT) times the number of attention layers (the “depth” of the model, which I explain more here). With 10 to 1,000 tokens per prompt, and roughly 100 layers, that’s just 1,000-100,000 operations instead of trillions. And since inference is only 1 pass rather than 6, querying a model is 8-10 orders of magnitude cheaper than training it— fractions of a penny compared to millions of dollars even for the largest models.
However, the weights associated with each token in the context window must be stored in memory. As context windows larger than 1,000 tokens are needed for queries that involve following through on complex tasks and remembering the types of requests we have made in the past, the practical size of these inputs when multiplied by an ever-larger number of parameters is constrained by the amount of memory available to do these inference operations. We will explore the implications of this in later sections.
The rapid rise and likely limitations of LLMs
13 trillion (1.3e13) tokens x 280 billion (2.8e11) parameters x 6 = 22 septillion (2.2e25) FLOP for GPT-4! What’s even more remarkable is that this is 100 times larger than the biggest model (AlphaStar) in 2019. Forget just doubling every two years! The recent trend has been almost 10x every two years 😲, thanks to increased investment. But how long can this trend continue?

By 2025, forecasters estimate5 that the largest training run might be between 3e25 and 1.2e26 FLOP (1.4x to 5.5x larger than GPT-4). By 2032, they estimate between 3.9e26 and 2.3e28 (~20x to ~1,200x larger). This is a bigger range of uncertainty than there is about processing power, because there are even more factors that may or may not limit the size of future training runs.
Training time and inference cost constraints
Further increases in model size mean that either computing power or the length of training runs will need to increase. But as mentioned earlier, conventional computing power per processor may only have one more order of magnitude of room to grow. And training runs longer than a few months are likely to be impractical. Increased investment seems like the most viable way to push through, as long as it is economically viable.
However, a bigger model also means inference is more costly. As of October 2023, it costs roughly 2 cents for GPT-4 to read a ~30 word question and give a ~100 word answer. A 10x bigger model would mean either a single query would cost 10x as much or take 10x as long, which is likely unsustainable given that ChatGPT queries already cost significantly more than Google Search ones. Decreases in computing power cost might make larger models more feasible, but other algorithmic improvements that maximize efficiency are primarily responsible for GPT-4’s faster-than-expected inference times.
Memory bandwidth
Memory bandwidth is the factor that keeps inference costs high for models past a certain size, and as mentioned above, is a significant constraint in developing models that are more personalized and can remember more about previous requests you’ve made. Improvements in memory bandwidth have also been significantly slower than increases in processing power. This constrains even what’s possible with increased investment.
To address this, recent efforts have focused on effectively reducing either the size of each FLOP (i.e. reducing the number of decimal places in calculations), or the overall number of FLOP needed to attain accurate results. When encountering estimates of FLOP/s, it’s helpful to know what the level of precision is6. Other algorithmic improvements to improve parallel processing of attention like FlashAttention might also compensate for this apparent bottleneck.
Limited data
There is also a limit to the amount of data available to use to train AI models. With current LLMs already approaching the size of the entire public internet, we may run out of high-quality text to train bigger ones as soon as 2024. Image and video data are still plentiful though and could continue to grow for another 20 years. This paper has an excellent illustration of the size and rate of growth of various modalities (text or speech vs. images or games).
Model size: the bottom line
Only the most aggressive predictions for 2025-20327 estimate that models will continue growing apace at their early 2020s trends. Given that improvements in processing power and memory bandwidth seem unlikely to accelerate, and the level of investment is already in the hundreds of millions of dollars for the largest models, I think the median forecasts of 2 orders of magnitude of further growth over the next decade (1 from hardware improvements and 1 from increased investment) are much more reasonable here. But even if growth in the size of the largest models cools off, there are many smaller models8 in development, and gains in their efficiency and effectiveness are scaling more quickly than anything else right now.
3. Accuracy and alignment
All of the computing power and data in the world is meaningless if we can’t use AI tools to do anything useful. While models at the forefront continue to improve according to various benchmarks, the degree of improvement varies significantly based on the task. Charts like the one below which track performance9 on various language and image recognition tasks make it seem as if AI’s abilities are either superhuman or rapidly accelerating toward that level. I explore these more below in my section about multimodality, but abilities like these, paired with how well they appear to be able to do creative work, are already affecting the livelihoods of writers and actors.
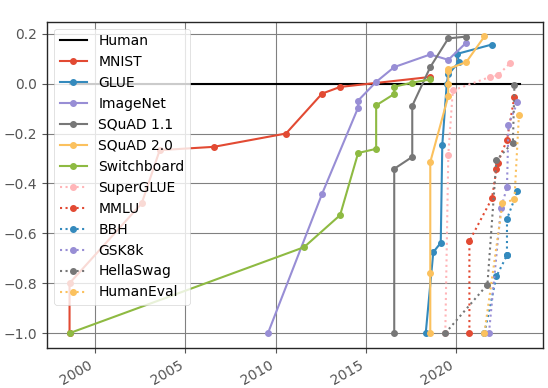
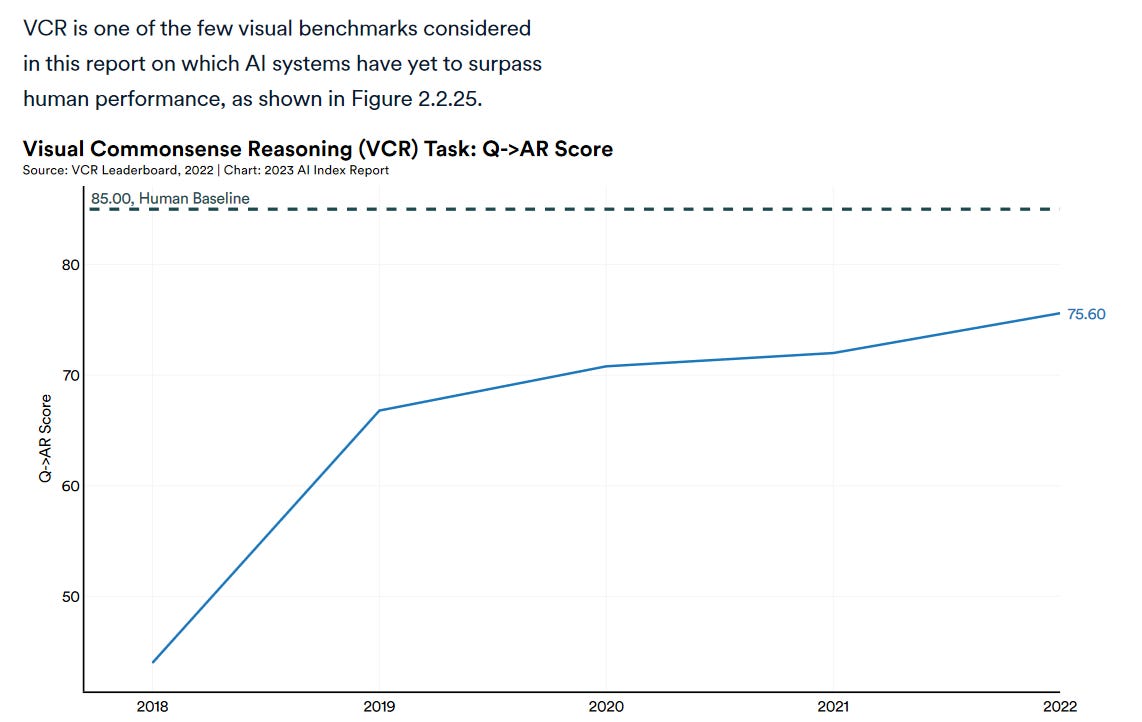
That said, there are other metrics where AI ability appears to level off below the ability of the average human, like visual commonsense reasoning10. For example, a state-of-the-art robot from July 2023 still struggled to understand the dynamics of certain objects, like how a round pen may roll when pushed, or the optimal way to push an object with an oblong shape like a banana. AI systems tend to struggle with other forms of reasoning as well, like understanding causality. While this piece from Qualcomm hypothesized causality being the “missing link” of the AI puzzle back in September of 2022, over one year later it appears that not much has changed, especially when you compare how much image-generation tools11 improved in the same time frame.
How to evaluate AI?
It’s clear that the simple Turing test proposed in the 1950s no longer captures the subtleties of where AI is improving most. Many of the examples cited above are tracked in Stanford University’s annual AI Index Report. This is an excellent source of information on many different AI-related trends, but this it is just one among many. Papers with Code shows progress across hundreds of different abilities in real-time, segmented by category, but it’s hard to know at a glance which benchmarks are most relevant12. Finally, LLMonitor provides an alternative way to view benchmark results— it will just show you what answers different models return to standard questions side-by side, albeit just for a few simple examples as of this writing.
While these benchmarks give us quite a bit of information about how AI’s abilities are improving, they also come with many problems. Questions from the test (or ones very similar to test questions) might show up in the training data, with the results potentially overstating an AI’s actual level of performance— this is referred to as “leakage” and it has created a significant reproducibility crisis. There is also the age-old problem of Goodhart’s Law— teaching to the test and then reading too much into the results. How can we get around these issues and ensure that benchmark results translate into meaningfully measured abilities to complete useful tasks in the real world? This is going to be a challenging issue to solve, but making progress here will allow us to make better predictions about AI’s trajectory.
One way of approaching evaluation is to think about some of the gaps in the current benchmarks. Measuring a model’s response to an immediate question based on the vast array of data it has been trained on is something that we might expect a computer to excel at. But this is a very different task from one that tests an AI’s ability to come up with multi-step plans and follow through on them in environments where new information comes up and constantly needs to be evaluated without catastrophic forgetting of the earlier context13. Admittedly, it might be hard for such a test to be standardized, but we will need to get creative. There is a lot to learn from the progress and pitfalls of other AI systems are already replacing significant amounts of human labor or coming close.
Example: measuring the safety of self-driving cars
Thanks to some more detailed analysis by Timothy B Lee, it seems like Waymo’s fully self-driving cars likely surpassed the safety record of human drivers, at least in the limited situations where they have been applied (3 million fully autonomous miles on the streets of San Francisco and Phoenix). If this is true, are self driving cars imminent? Why does this prediction market still have a wide range of uncertainty (between 2024 and 2030) about when they will be widely available?
The uncertainty comes from two sources:
3 million miles is still not a whole lot of distance when it comes to fully comparing the statistical safety of self-driving cars against the trillions of human-driven road miles each year in the US alone, so error bars on these initial reports are high.
Public trust may be wavering and could be tricky to maintain as even statistically safer cars would still cause headline-grabbing accidents.
That expansions in service to several new cities were announced in August 2023 means that the next 3 million miles should come much more quickly than the first. And better transparency on several levels could help improve the public trust needed to continue piloting this technology:
Cleaner independent visualization of government data about self-driving car accidents, contextualized alongside human accident rates.
More willingness among self-driving car developers like Waymo to share more detailed internal data about how their vehicles handle exceptional situations.
Tracking other externalities like those outlined in this report. To what degree might the cautious driving style of self-driving cars and other technical errors be responsible for slowing down traffic? How much of a risk does hacking pose?
What prediction markets tell us about other AI capabilities
Just as prediction markets can be helpful in visualizing when self-driving cars might be available, they can also help us understand progress in other transformative technologies, and how the latest news impacts their timelines. Of the many AI prediction markets out there, this one is my favorite because it assesses practical skills and not just exam results of a more “general” AI. As of writing this in September 2023, this market estimates a 25-75% confidence interval between 2026 and 2045, following the 2024-2030 window for self-driving cars. If the 2030s are as wild as this detailed forecast, how can we prepare ourselves for the tumultuous times ahead?
An idea for improving AI benchmarks and predictions
Reports by Goldman Sachs and McKinsey from the spring of 2023 take a look the impact of AI’s generative abilities on the labor market and economy at a fairly detailed level, allowing for some uncertainty in how capable generative aspects of AI will be. McKinsey has since followed up with a survey tracking AI use by industry and job function. However, some of the data behind their analyses are understandably private, and these only capture a moment in time in a period of substantial technological change. How can we make publicly-available forecasts more agile?
What if we had something that combined the granularity of the Goldman Sachs report (which looks at O*NET’s inventory of the knowledge, skills, and abilities required for hundreds of different occupations)14 with the constantly updating nature of a prediction market? What if any unexpected delays or sudden leaps in progress could be better contextualized? Imagine, if you will, a site like willrobotstakemyjob.com, where you could see links to AI’s latest progress on various tests relevant to each occupation, make bets (a la Robin Hanson’s Robots-Took-Most-Jobs insurance?), and discuss? I find the work being done by Stanford’s HELM team, the BEHAVIOR benchmark for robotics, and this research that measured how much use of ChatGPT augmented workers across a variety of tasks very intriguing, and would love to help realize a multidisciplinary project like this! 15
Understanding ourselves better to keep AI safe
As we continue to make progress in assessing AI’s capabilities, I expect we’ll continue to reveal unexpected insights about ourselves, and what makes us “intelligent”. Many new capabilities that are developed may be double-edged swords in that there is also potential for significant harm, whether from technological unemployment, algorithmic bias and other ethical considerations, or the potential to aid bad actors. The debate over which of these threats among others are the most salient is hotly contested, but it’s clear that regulation of AI will need to span many domains. Better tools for tracking AI progress could help us understand the comparative advantages we are likely to continue to maintain as humans, and make this regulation more attuned with the reality of possible threats.
4. Algorithmic efficiency
Where accuracy is defined, “algorithmic efficiency” can be calculated. Processing power and model size are fairly straightforward measurements, but if we were to imagine how much accuracy might still improve even if these didn’t change, we could calculate how much more efficient AI has become. Epoch AI also did an analysis of this and the results are impressive— every 9 months, the introduction of better algorithms contribute the equivalent of a doubling of compute budgets, at least for image recognition.
But “algorithmic efficiency” is a nebulous term. Below are five categories I’ve found helpful for classifying the various gains in performance we might see from aspects of AI not related to better hardware, training larger models, or using architecture that is fundamentally different from current transformer models (fundamental changes in architecture, like the shift to transformers that occurred in 2017, could be considered a sixth type of “algorithmic improvement” to look out for16):
Pruning data and sparsifying parameters
Pruning data: The quality of data that a model is trained on may vary considerably. An appropriately curated subset of that data (as long as it has sufficient diversity in terms of subject matter) can lead to similarly accurate answers but require much less computing power, such as this one that achieved similar accuracy after pruning 25% of its original dataset, and revealed some insights into which examples are best to keep based on a dataset’s original size. Given the billions of data points that are generally involved in training a model, AI naturally assists with this pruning.
Pruning parameters: Alternatively, creating a “sparser” model that can selectively ignore parameters that are less relevant to each batch of data, or route them to an “expert” that specializes in a subset of them (as GPT-4 does) improves efficiency in the other compute-heavy dimension of a model. For example, in March 2023, SparseGPT revealed little loss in accuracy even after roughly half of its parameters were effectively pruned, and WANDA, an even more economical pruning approach was proposed three months later.
A mixture of both: Focusing a model on a specific domain with high-quality inputs can reduce the compute needed for both dimensions (data and parameters), as this model 8,000 times smaller than ChatGPT’s free tier performed just as well or better in the specific domain of answering Python coding questions. There is a strong argument here though that data-driven (rather than parameter-driven) improvements will have the most impact.
Fine-tuning
Layers: If we can imagine the number of data points and parameters as the length and width of a model, we can think of the number of layers it uses to transform an input into a desired output as its depth. A model that gives reliable answers in one domain can be fine-tuned for another one by peeling back and retraining some of its layers closest to the output with data related to its new task.
Attention: Different “attention heads”, which are each tasked with looking out for certain subtleties in the use of language, interpret the input and transform the potential output at each layer, and can be adjusted as well. There is a limit to how much content these can ingest at a time, though developments like the “Hyena operator” may allow for a model to be able to take in a larger context window, which has implications from improving personalized AI to long-term planning to solving more advanced problems in genomics.
Different methods for fine-tuning: A model can be fine-tuned on a new dataset that is more specific to a new task it is expected to accomplish. In some cases, this can be done by simply giving the model some specific instructions. Otherwise, using interactively-generated data coming from human annotators, and providing the model with feedback on its responses can be a powerful but labor-intensive approach. This last method is known as Reinforcement Learning with Human Feedback, or RLHF.
“Self-improving” AI techniques: Fine-tuning can be automated such that AI is able to improve itself, though this does involve some structure beforehand to prompt the model to ask itself questions that include example answers (AKA a “few-shot”17 approach) and instruct the model to provide its answers in a way that spells out each logical step (AKA chain-of-thought reasoning). These are also techniques that help people get higher-quality answers from AI, and can be used across different domains— similar self-improvement has been seen in robotics.
How much self-improvement are we actually seeing? The optimistic case for self-improvement is that models appear to be at or above human level for many simple data curation tasks. The pessimistic case is that models may not be as successful at curating the data needed to accurately perform more complex tasks, and that human error and bias in annotation might constrain progress even in manual improvements. A list of other risks of self-improving models can be found here.
Interpretability features
For all of the impressive features that 2023 AI models have, interpretability, or the ability to understand why a model made the choices it did, is one of the biggest shortcomings. ChatGPT doesn’t cite its sources, and even tools like perplexity.ai only provide links without going into more detail as to why those sources were used and not others.
The number of layers and attention heads make a model’s decision-making exceedingly difficult to disentangle, which can make it harder to trust the outputs. This makes interpretability one of the more labor-intensive and subjectively evaluated areas of AI research in 2023. You can get a real sense of the complexity of this field from reading this get-started guide.
Breakthroughs in interpretability might be heavily incentivized particularly in fields like medicine where AIs might eventually perform better than human doctors, but still make errors that will need to be explained. There is also a high level of interest in interpretability from junior researchers in the field, and over 1,000 papers are published about interpretability each year.
Interpretability may unlock other benefits as well, though some of these are contentious, and there may be a long way to go to get there.
Multimodality
One of the aspects of current advances in AI that has surprised experts the most has been how transferable LLMs’ abilities are across domains. This aspect (called “transfer learning”) can greatly accelerate progress by making it easier to fine-tune existing models, and allowing for machines to understand plain-English instructions rather than requiring other specialized code. Here are a few of the most significant examples:
Translation between languages: LLMs can understand non-English languages relatively well in spite of these languages making up only a tiny fraction of their training data (which is still mostly in English). As of 2023, they are better at translating into English than the other way around, though they have not yet achieved the level of accuracy of professional human translators.
Understanding similar concepts across text, code, and images: In May 2023, Meta released ImageBind, foundational code which would allows for translation across different modes of communication entirely: for example, a short video of a train could be generated based on the sound of a train horn. An impressive example of a 100% AI generated short video from July 2023 can be see here— check out the description to learn more about the tools used for the story, images, video, narration, sound effects, and subtitles.
Moving around in the real world: an AI system that can translate between modes and follow natural-language instructions can go from navigating itself around in a virtual environment to moving around in the real world. This multimodality brings further advances in self-driving cars as well as other kinds of robots. In July 2023, a new way to translate images and language into robot actions was developed that allowed a robot to achieve a similar level of accuracy as one that was trained on over 10x as many parameters just a few months earlier, though like other systems it still struggled with commonsense reasoning.
Medical applications: there are even more streams of information that AI models can process in the medical field, from interfacing directly with the brain to proposed moonshot projects like modeling every single possible molecule for drug discovery and building an AI model of the human body down to the cellular level. Important new breakthroughs are regularly published here, and range from specific applications18 of AI to new tools to expansions of these capabilities from one tool to another to new systems that are generally knowledgeable across domains. While some of these systems might be just specialized versions of ChatGPT, Foundation models for Electronic Medical Records (FEMRs) are another important variant. FEMRs use longitudinal health data to make predictions about a patient’s prognosis. And beyond medicine there are many other applications that scientists in general are both excited and concerned about.
Human skill at using AI
While human skill isn’t an algorithmic improvement in the strict sense, as people get better at using AI-powered tools, it will appear as if their performance is improving as well.
The starting point: Just as people a generation ago didn’t become proficient at using computers overnight, there is a learning curve to making the most out of current AI technology too. As of July 2023, only 24% of Americans who’ve heard of ChatGPT have used it, and an even smaller percentage have used it for work or learning. There is still a long way to go here, though adoption has been a lot quicker than with previous technologies.
Prompting skills: Techniques used by AI researchers to get better results when testing their models, like providing examples of answers to similar questions, or simply asking the AI to “take a deep breath and think step-by-step” can help everyday users get better results as well. Ethan Mollick shares some even more sophisticated prompts here— imposing some constraints and providing more detailed information about the intended audience can greatly improve the quality of the response19.
Imagining where AI can be applied: As we explored in the above section about multimodality, AI tools aren’t just chatbots! From image generators to robotic lawnmowers, the many use cases for AI will challenge our imaginations for years to come. Maggie Appleton has done some interesting conceptual work in this area, envisioning how we might make use of AI to challenge our assumptions and get better feedback on our ideas20.
Baking AI into everyday products: from the imaginations of designers, we can expect to be deluged in the coming years by AI-powered products both useful and overhyped. “Copilot” tools have already been used in some areas to great effect. Depending on the metric used, GitHub Copilot has increased the productivity of software developers, particularly more junior ones, between 25 and 55%21, and 75% of its users felt more satisfied. Similar tools are rapidly expanding to other sectors like sales, marketing, and customer service work with Salesforce’s Einstein Copilot. An expanding number of AI-connected extensions22 bring these tools into browsers, and even operating systems are getting an upgrade. Meanwhile, ChatGPT’s functions are expanding thanks to an emerging universe of useful plugins, including Advanced Data Analysis (formerly know as Code Interpreter). There are some excellent examples of how to use this here— I expect this tool will help me finish my upcoming analysis of the BLS’ latest employment projections much more quickly than I’d originally expected23.
Meta-skills: As AI tools get better, it’s important to be aware of what tasks AI isn’t an appropriate solution for, and recognize where reliance on automation might atrophy our own skills. These are important concepts to teach AI agents as well. A recent collaboration between Google and Deep Mind explored when a tool might accept an AI-generated diagnosis vs when it might ask a human professional. But quantifying the uncertainty and knowing what an AI might get wrong isn’t easy. There is a quiz you can take to guess if GPT-4 got various questions right, and it is surprisingly difficult to do well. My hope is that with a better way of assessing AI’s abilities relative to ours in real-time, we will also become more knowledgeable in this area.
It matters where AI improvements come from
If the most dramatic improvements continue to come from easily sharable techniques for more effective use of data and parameters, and models continue to surprise researchers in their abilities to adapt to novel modes, powerful AI is less likely to be constrained by computing power and the cost of human labor. This has sparked two major concerns:
Concerns from investors that large AI companies may have less of an advantage than they had originally assumed.
Concerns from security experts that small-but-powerful open source AI tools could be harder to regulate and make it easier for bad actors to wreak havoc.
As an example, the computation power alone to train the premium GPT-4 is reported to have cost between $32 million and $63 million. But it’s important to note this is likely only a fraction of OpenAI’s operating expenses, which totaled over $540 million in 2022. While its energy costs are likely still under $10 million/year according to these figures, many of its employees (375 as of early 2023) make nearly $1 million/year, and much of the remaining spend likely goes toward outsourced contracts for data annotation24. As much as compute might be bottlenecked, it seems like skilled AI researchers are in even shorter supply25 as labor still appears to be the biggest part of the cost of training a state-of-the-art LLM.
If this continues to be true, we might expect the trajectory of AI to be rather similar to ordinary software, with open source26 tools like Facebook’s LLaMA and its descendants being used for some applications and closed-source tools being used for others. Still, a key variable to follow over time (and something that should be more robustly tracked) might be the gap in performance between open and closed source tools as this summary from Charlie Guo outlines. Such a variable, being inclusive of AI’s overall performance and usefulness would heavily influence the nature of our fifth big variable to watch: investment.
5. Investment
At a high level, global corporate investment in AI increased 5-fold between 2017 and 2021. There are a few parts to this story, including a preface about the scale of these dollar amounts:
What can the market tell us about the future of hardware, software, robotics, and the economy as a whole?
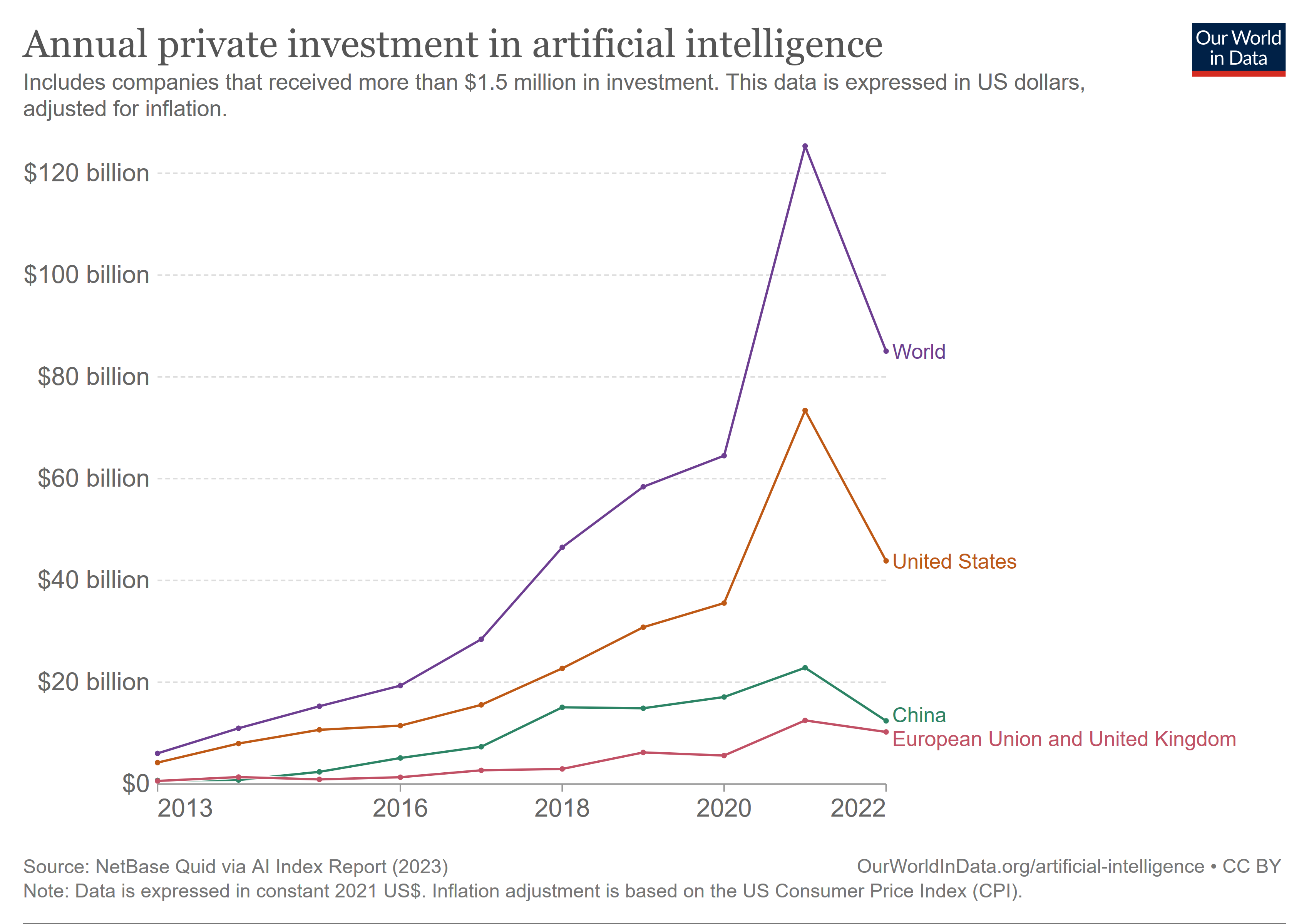
The scale of investment in AI
Staggeringly large numbers, whether exaFLOPs or billions of dollars can be hard to imagine without better context. US private investment in AI in 2022 was $47 billion. That’s equivalent to:
About 8% of all US software investment
0.2% of total US GDP
0.2% of GDP is still a relatively small sum compared to how much we hear about AI, and how much it might impact daily life. But by 2032, this Bloomberg report suggests that the revenues of the generative AI industry could be as high as $650 billion in the US alone27, or $1.3 trillion globally, which would be close to 2% of 2032 GDP (assuming a continuation of average economic growth, though US investors appear to expect more). Forecasters of total global corporate investment in AI on Metaculus make a prediction similar in scale.
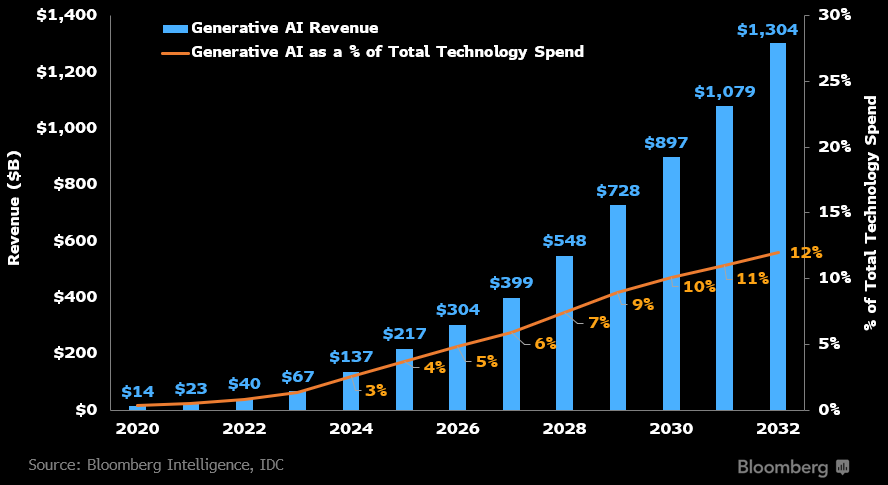
How does this compare to historical trends?
US private investment in software passed 2.3% of GDP in 2022 and has continued to grow from there. To grow by an additional 2% of GDP within a decade would be unprecedented— even the software boom in the 1990s only amounted to 0.75%, or 1.3% if you include hardware equipment as well.
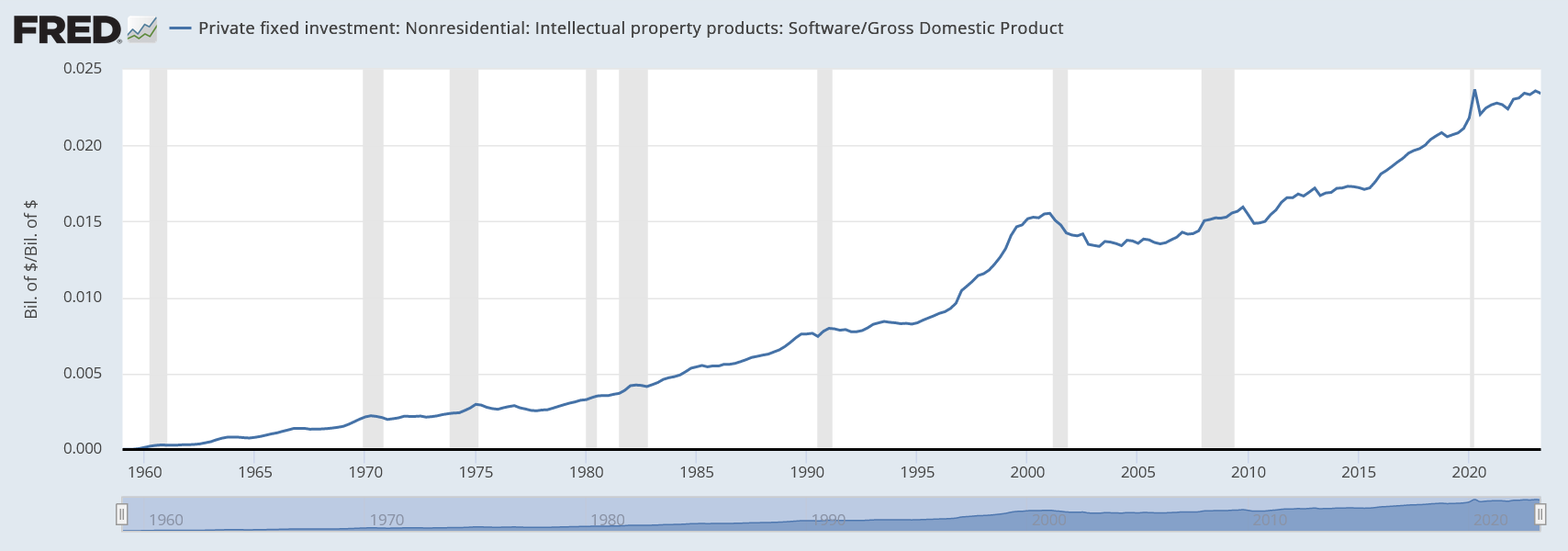
Knowing how useful AI copilots have already been for software developers though, we need not think of AI as entirely separate— it will almost certainly “eat” a certain amount of software spend such that the overall increase might only be somewhat higher than what we saw in the 1990s. And there are many interesting comparisons one may draw here. As Rex Woodbury puts it:
The internet blew open the gates of distribution
Generative AI blows open the gates of production
It took time to build the infrastructure of the modern internet, teach people how to use it, and eventually change habits (for better or for worse) such that the average American spends 6.5 hours per day looking at internet-connected screens. This infrastructure both physical and cognitive is what has allowed AI tools to be adopted at record-breaking speed. That the network for distribution is already in place is what allows for more aggressive predictions.
The start of the boom and the 2022 slowdown
Earlier, we saw that the largest AI models grew 100-fold between 2019 and 2023. This was enabled by the five-fold increase in investment that happened 2 years earlier between 2017 and 2021, as we saw in the first chart of this chapter. The extra investment was complemented by a tripling in price performance in that same time, just a little slower than Moore’s Law.
3 times 5 doesn’t add up to 100 of course, so it’s notable that the concentration of investment in computing power also increased. We see this in GPU-maker NVIDIA’s revenue, which also tripled from $9 billion to $27 billion between 2017 and 2021, largely from sales of its chips to data centers specialized in training AI models.
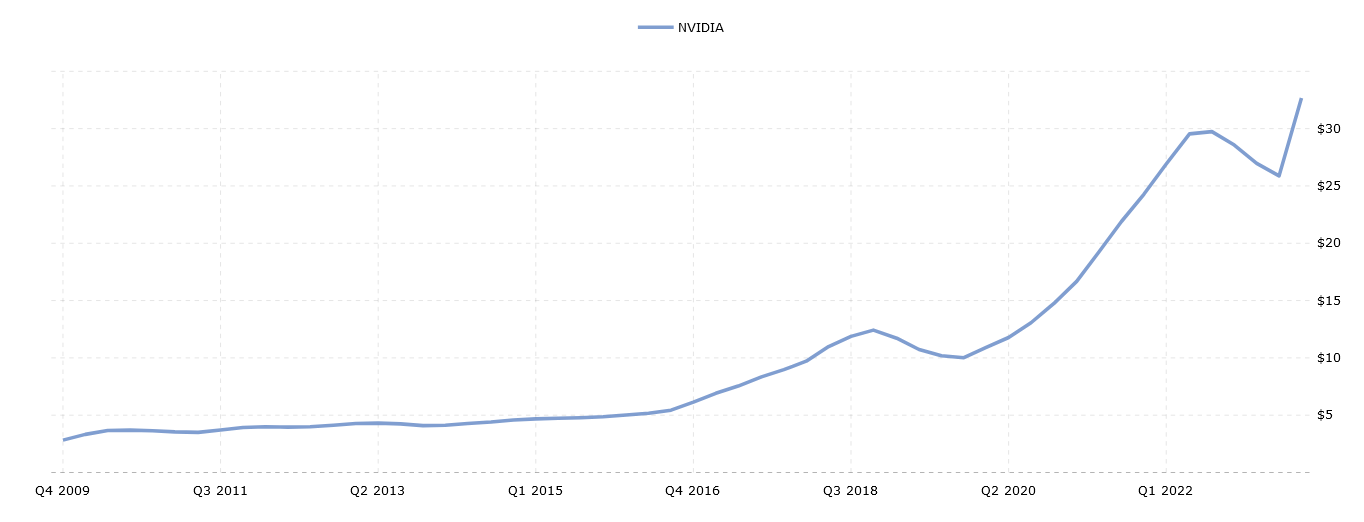
Similar to the dip in overall investment, NVIDIA’s revenue also dropped slightly in 2022 as higher interest rates took hold and demand from cryptocurrency mining took a hit, but Q2 of 2023 saw a record increase as investment accelerated again.
2023’s growing clash between giants
Just as rate increases slowed in the spring of 2023, the apparent value of generative AI was enough to motivate an even larger wave of investment in hardware than before even as venture funding continued to decline. While Sam Altman of Open AI stated that it would be “some time” before we see GPT-5 in June 2023, just one month later, the company filed a trademark for it with the US Patent Office. Google’s Gemini, which could be at least 5x larger and more multimodal than GPT-4 is expected to be released in December. This could put some pressure on OpenAI to roll out something new if they haven’t done so already by that point.
This competition between OpenAI/Microsoft and Google will be interesting to watch. While visits to ChatGPT have plateaued since May 2023 (and fallen a bit during the summer while schools are out), it still gets about as many visits as Netflix, more visits than any single news website in the world, and over 10 times as many as Google’s current competitor Bard.
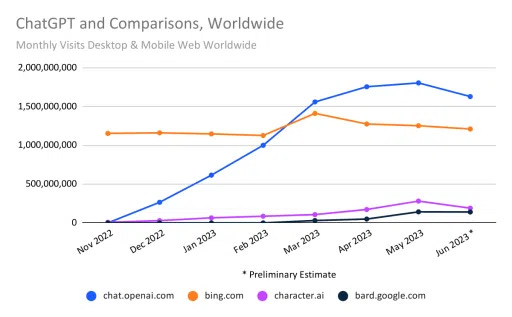
But Google Search still gets nearly 50 times as much traffic as ChatGPT. If their sizeable cash and data advantage allows them to provide useful features to their large user base across their many products (and find a way to make LLM-powered searches economical) it will change the trajectory of AI.
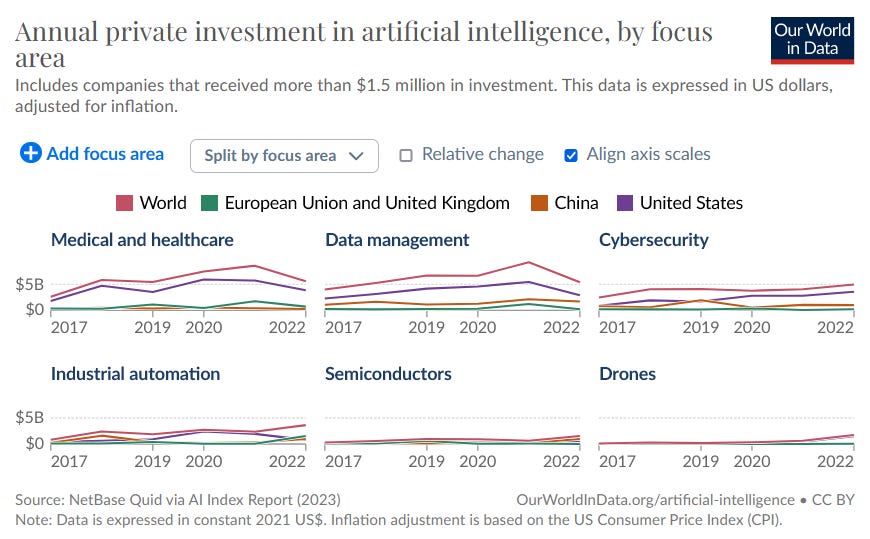
Of course, these companies are only two in the wider universe of tech. It’s important to note that not all areas of AI investment declined in 2022. Indeed, there are many use cases such as cybersecurity, industrial automation, semiconductor research, and drones that are just starting to take off.
What can the market tell us about the future?
NVIDIA’s stock price grabbed headlines in mid-2023, and OpenAI’s $80-90 billion dollar valuation also turned some heads. The valuations of both of these companies— one hardware and one software— tells us a lot about both the excitement and concerns of investors. Thinking about growth in these industries can also help us better contextualize the progress in robotics.
Hardware investment
On the hardware side, as of October 2023, NVIDIA’s stock price stands at over 100 times its total earnings per share over the previous year (AKA a P/E ratio of over 100), or about 4x higher than the market as a whole. Of course, its frothy valuation is based on its Q2 earnings, which represent a significant jump in its data center sales.
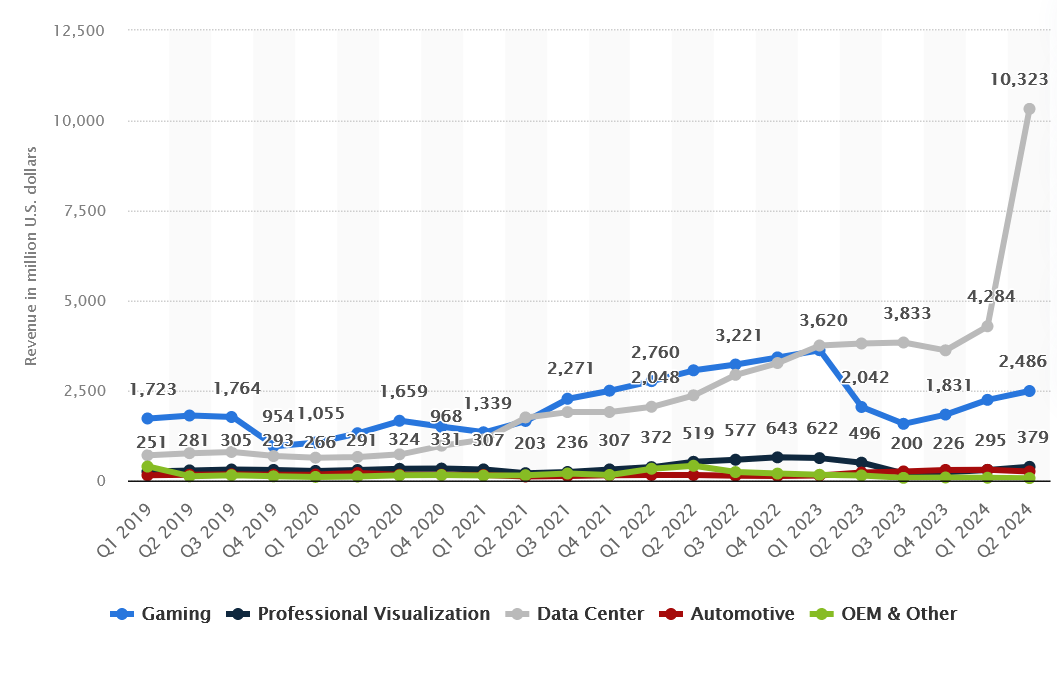
Many analysts expect these to grow as time goes on. But even if we just held Q2 earnings as they were for the rest of the year, a $432/share price puts its forward-looking P/E ratio at a much more reasonable 4028.
Looking at things this way, it seems like NVIDIA’s earnings would only have to double in order to get back to the forward-looking market average. Given various growth projections from 23% to 74% annually, this could be achieved in 1-3 years. But there are a few risks to look out for:
Demand for chips: this is contingent on AI models continuing to scale up as we explored above. The optimistic case is that as models move from text to the data-heavier formats of image and video, more compute will be needed. Image generator Midjourney’s ambitions include generating real-time video and even custom video games, but their CEO has indicated that more computing power is needed to achieve this. Tesla plans to build a computing cluster more than 10 times larger than OpenAI’s by 2025 to more extensively use the millions of hours of driving videos its cars have captured over time for training purposes. It’s important to recognize that inference costs computing power as well as training, so any significant user growth would imply a need for more computing power as well. Recognizing this source of demand, NVIDIA’s upcoming GH200 GPUs will have 230 times the GPU memory, and will be even more specialized for inference than the current H100s.
On the flipside, Midjourney has been able to create a very impressive tool for a model that only costs $50,000 per training run, and if Tesla is able to bring full self-driving cars to market based on its 2025 investment, it’s not clear how much more computing power it would need after that. Economy-wide, it could be that all it takes is a spike of initial investment (in GPUs in this case) to make meaningful increases in productivity, as was the case for both electrification in the 1920s and PCs/internet in the 1990s.
Broad vs narrow demand: will growth in demand for computing power be dominated by a few leaders, or more broad-based? Looking at the Top 500 supercomputers, growth in top computers appears to be outpacing the growth in the 500th fastest one, but this could be an informative difference to watch over time, albeit a lagging indicator.
Competitive pressure: the rush to buy GPUs has brought NVIDIA’s profit (net) margin from 19.2% to 50%, but this is unlikely to hold over the long run. Retaining the overall level of earnings at the likelier long-term margins means revenue would have to at least double, if not 10x, unless NVIDIA’s “moat” is wide enough to keep both its high margins and dominant market share (91.4% of the enterprise market in 2021). The margins of the semiconductor industry on average are only 5.6% which could be a risk if other companies become competitive (including both NVIDIA’s OEMs and even their customers), or if there are breakthroughs in new computing paradigms that NVIDIA is not invested in. On the other hand, NVIDIA’s R&D spend is nearly 20% higher than its closest competitor AMD, even after accounting for gross revenue. This budget may allow them to continue to maintain their advantage in specialized improvements that sparsify parameters at the hardware level, attacking the memory bottleneck mentioned earlier.
Altogether, it seems like a bet on NVIDIA in the $430/share price range given Q2 2023 earnings is a bet that recurring demand for computing power will grow between 5x and 20x and remain there, on top of the 10-20x predicted improvements in price-performance over the following decade. This is roughly in line with Metaculus forecasts for the largest as well as the most expensive training run, both of which include considerable uncertainty29.
Software investment
On the software side, OpenAI has been reportedly valued at $80-90 billion in spite of only a little more than $1 billion in revenue and $540 million in expenses, implying an even higher P/E ratio near 200. How can it be worth that much?
It’s important to remember that growing software companies are often valued much higher than companies that manufacture physical components. Additional copies of software can often be sold at very little additional cost after an upfront investment, and customers might not be able to switch so easily once a solution is chosen. As an example, Salesforce’s P/E ratio has frequently been north of 100, and now they have a major AI product as well. Broadly though, considerations for investors in AI software are similar to those for AI hardware— demand and competition:
Demand for large AI models and related services: For this, we may also want to think back to the Bloomberg prediction. If generative AI revenues do indeed grow 10-fold relative to the overall economy by 2032, a 200 P/E ratio shrinks to a 20 (below the market average of 25) in just 9 years, though only if the profit margins remain the same. Given the many applications of AI in software development itself, it’s possible that software may become significantly cheaper, increasing demand but also competition. On the other hand, if it becomes significantly harder to achieve a high enough level of accuracy for more advanced applications, the demand for generative AI in general could begin to stall. An early indicator of this might be the slowdown of new ChatGPT Plus subscriptions in September 2023.
Competitive pressure: as we explored above, if open-source models can be competitive with state-of-the-art ones, knowledge about how to best deploy AI for each use case could trump having a big general model. Those who believe this tend to invest in smaller companies rather than making investments in large ones. Midjourney is an example of a company that has already generated $200 million in revenue as of September 2023 with 40 or possibly even fewer employees with no outside investors. But as the competition between Google and OpenAI shows, having a large user base and a first-mover advantage can also be decisive.
Robotics investment
It seems like we hear a lot about AI, but not as much about robotics in 2023. Compared to 2022’s global private investment in AI of $85 billion and revenues of $40 billion in 2022, what does the global market for robotics look like?
The International Federation of Robotics (IFR) collects numbers on robot installations, but there doesn’t seem to be as centralized of a source for how much is actually invested in the industry, at least globally30. Based on information from a few different reports which I’ll reference below, my best estimate for this is $69 billion in 2022, just a little less than AI. Growth projections are also slower at 17% annually which would put the total market at $286 billion by the early 2032, only 1/4 of the forecasted size of generative AI market. That said, within robotics there could be some breakout sectors. Let’s take a closer look at the three major categories in this industry:
Industrial robots: with 553,000 units sold worldwide in 2022 at an estimated total cost of $26.5 billion, each robot cost $50,000 on average31. This was a 5% increase over the year before, much less than the 10% that was predicted previously. It’s important to note that more than half of all industrial robot installations happened in China32, and there was a big jump there in 2021. However, with manufacturing construction picking up again in the US, might more robot sales soon follow? The IFR’s World Robotics 2023 report estimates annual global growth going forward at 7%, but another analysis that was published by Bloomberg suggests it could be as high as 10.5%.
Professional service robots: this market includes robots in the fields of transportation & logistics, hospitality, healthcare, professional cleaning, and agriculture. There are some excellent visual examples of these in IFR’s 2022 report. While the absolute number of new service robots installed worldwide in 2022 was just over a quarter the total of industrial ones at 158,000, the total cost of these came to $21.7 billion33, and grew by 48%, after 37% growth in 2021. Seeing such growth in spite of the $137,000 average unit price makes me wonder if the 21.6% growth forecast for this sector is too conservative.
Consumer service robots: these include the sorts of robots you might buy for work and fun around the house, from Roombas to recreational drones. It is the smallest market financially, at $10.4 billion in 2022. However, it is the largest market in terms of number of total units at 19 million for vacuuming and lawn-mowing robots 2021. While the growth projections from Statista seem to suggest this market is cooling off to growth rates around 5%, it will be interesting to see if recent advances in multimodal AI make these sorts of robots useful and/or cheap enough for more people to want to buy them.
While the market for GPUs is dominated by NVIDIA, and the market for generative AI is associated with several well-known companies while everyone else figures out how to offer AI themselves, the robotics market in 2023 is much more fragmented. Overall, it seems like there are 5 different types of companies in this space:
Companies with long histories in the automation space like Omron, an early manufacturer of electronic ticket gates and ATMs
Companies who make industrial robots as well as many other types of electronics and related components like ABB
Other established companies like Intuitive Surgical that make robots for specialized use cases in healthcare
Robots-as-a-service (RaaS) companies that allow operators to test robots out before committing to a larger purchase
Startups working on a variety of specific challenges (2013-2016 were boom years in the robotics startup world)
If growth in service robots continues its recent trend of 40%+ each year, it would bring an additional 15 million new robots online by 2032, and the total robotics sector to over $700 billion, over half of AI’s projected revenue instead of just a quarter. Such growth would beat market expectations— between 2019 and 2023, robotics-focused funds tended to slightly under-perform the S&P500 unless they had heavier exposure to AI-focused stocks. Could this be an example of investment in AI “crowding out” robotics? And is the 66% growth in the RaaS market a leading indicator of more companies trying out robots for their operations?
As we explored in the earlier section about multimodality, AI and robotics are likely to see even closer synergies in the years to come. However, there are still quite a few unsolved challenges that this detailed review of the literature on robotics explores. This is something I’m looking forward to diving into deeper in a future piece.
Investment: the bottom line
In an economy where interest rates are higher than they’ve been since the 2001, investment in technology is quite different than it was in the 2010s. While Amazon was still consistently losing money in most quarters as late as 2013, both OpenAI and Midjourney are well-known AI companies that are already profitable in 2023. With higher interest rates, venture funding is down, and companies have to prove their value more quickly than they did a decade before. Yet interest rates were similarly high in the 1990s and the dotcom bubble still happened. And it’s important to mention that not all AI ventures are profitable— Microsoft’s GitHub Copilot reportedly loses more than $10 per month per user. How can we assess if the stock market overall is fairly valued or in a bubble based on the promise of new technology?
While the early beneficiaries of AI have been leading 2023’s stock market gains as one might expect, a chart that really caught my eye was the one below that compares the overall S&P 500 forward P/E ratio (a possbily risky asset) with 10-year inflation protected yields (TIPS, a very safe asset).
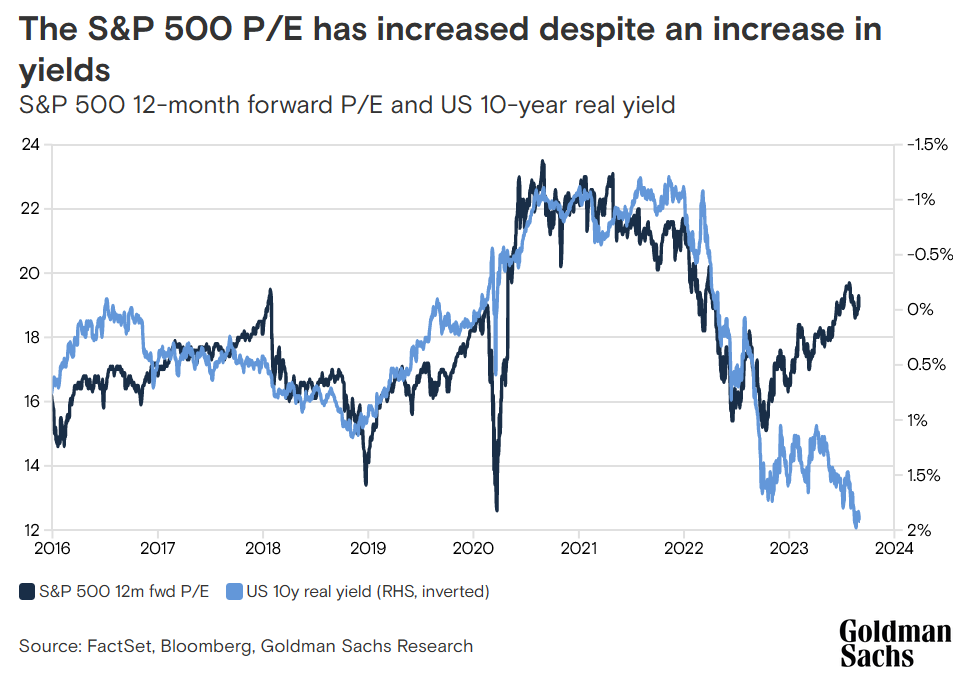
One of the axes is flipped, so we see that the trends are a close inverse correlation with one another. There was an equilbrium in the late 2010s where forward P/Es were around 17 and TIPS were around 0.5%. TIPS fell to -1%, with stock valuations conversely rising about 30% to 22 during a pandemic-era equilibrium. After a brief period in mid-2022 where the pre-pandemic equilibirum was restored, these trends started sharply diverging from each other in late 2022, around when ChatGPT was released. Now, TIPS have risen 1.5%, but rather than fall by 30% toward a forward P/E ratio of 12 as the trend might have suggested before, stocks have continued to rise toward 19!
If we take the P/E ratio of the previous equilibria to be 5.8% and 4.5% respectively, and compare that to the TIPS of 0.5% and -1% respectively, we see that historically, investors expect 5-5.5% additional returns for the risk of investing in the stock market. With TIPS approaching 2.5% in October 2023, that means investors are expecting 8% returns from stocks over the next 10 years, or 2% higher earnings than usual. This is on the high end of the 0.3% to 3% range of additional annual productivity growth that the April 2023 Goldman Sachs report suggested. As economist Tyler Cowen points out, even this additional 2% of growth per year that the market has priced in is historically exceptional.
If you were to invest just in the stock market in general given this information, what would you do?
If you believed that AI would lead to no greater than normal growth, you might think that we are in a bubble and the stock market could be as high as 50% overvalued given the relative safety of inflation-protected Treasury bonds. On the other hand, if you believed that AI might someday bring us anywhere close to an unprecedented rate of 30% annual GDP growth34, you might think that the current market is still quite a bargain. As with many of the predictions we have explored so far, there is quite a range of uncertainty. Reading through detailed reports like the Goldman Sachs and McKinsey ones, and comparing their predictions with your experience I think is the best way to assess if the market (or any individual investments you might be considering) are fairly valued35.
While the financial markets can give us a good indicator of what wealthy investors think will be valuable, and observations about computing power and algorithmic improvements can give us a sense of how the capabilities of new technology might evolve, it’s important to not treat these forecasts as wholly deterministic. Ultimately new technologies will ideally be shaped to serve the common interest based on public opinion and regulation, our sixth and final variable.
6. Public opinion and regulation
As we wrap up this deep dive into AI, it’s helpful to look back at the other key variables we’ve considered and how public opinion and regulation impact each one:
Increases in computing power have been fairly predictable for the past 60 years, but the threat of geopolitical conflict looms over the industry. The strategic value of semiconductors has led to export restrictions and new industrial policies designed to secure a reliable supply. Some have also argued for computing capacity restrictions for individual actors.
Increases in the amount of data that’s collected (and later fed into AI models) can be modeled, and the contents of what is stored will depend on privacy and copyright laws. Beyond legal restrictions and questions about what is considered “fair use” of copyrighted work, individuals and companies are also moving to limit the publication of their own data into the public sphere. Larger AI models will naturally attract more scrutiny.
We should expect the software behind AI to continue to become more powerful, though as we explored above, there are many worries that open source AI tools will be difficult to regulate.
AI’s abilities continue to improve in many areas, though there are some notable weaknesses. Regulations about the sorts of decisions that AI systems are allowed to make play a role here, as do keeping a close eye on any externalities that seemingly competent systems may introduce, from traffic jams to increased cybersecurity threats36. Intelligent regulation will rely significantly on lawmakers’ understanding the current and likely future state of AI abilities, and there is naturally a great deal of concern here about the future of employment.
As the level of investment in AI increases, so to will opportunities increase to regulate operators above a certain size. Governments might also change the amount they invest in R&D in the field as they investigate their own AI use cases.
However, there is one type of regulation that doesn’t fit into the above boxes: rules and norms that govern accountability, ownership, and agency.
Accountability, ownership, and agency
Who is accountable when problems arise? As AI-powered systems move from generating funny images of cats to making life-and-death decisions on the streets, this question grows more important every day. The number of AI-related legal cases continues to grow rapidly, and cases about the liability of self-driving cars might inform how liability is settled in other cases of embodied automated systems.
Who owns the intellectual property that autonomous systems create is another matter of intense debate. In 2023, the US Patent Office has ruled multiple times that AI-generated artwork is not eligible for copyright, but Timothy B Lee makes a strong case here for AI-generated artwork being analogous to photography (which after some legal battles when it was a new technology, ultimately became eligible for copyright in most instances). Significant changes in the Patent Office’s ruling would have a big impact on the business applications of generative AI.
The accountability of AI systems, as well as people’s level of trust in them, will influence the overall level of agency these systems are accorded over time. AutoGPT, an AI application that you could use to, among other things, order a pizza was released to much fanfare in April 2023. Though interest has declined since then, frameworks like LangChain have been developed to allow applications that use AI to cross various modalities and better “remember” what they need to do across chains of tasks. As AI systems are increasingly connected to eyes and ears, it would be interesting to measure how much money they have direct access to over time as a barometer of the public’s trust in this technology. If such a system does something unintended, when is it the fault of the user vs the fault of the developer? Vicarious liability theory, and considerations about who is responsible for each layer of an AI are relevant for these sorts of questions. There is an excellent summary of these concepts here.
In imagining how complex agentic systems deployed on a broader scale might play out, the history of algorithmic decision-making assisted by machine learning in stock trading could be an instructive example. These systems already account for a vast majority of daily stock trades, have an extensive history of regulation, and have already had to deal with challenges like being vulnerable to misinformation on social media. An important question to account for though, is how well do systems whose use is regulated within a company scale down to personal use cases?
To help us visualize what a more automated future might look like, I’ve proposed a heuristic similar to the classic “Eisenhower Matrix”.
A way to think about automated decision-making

Routine, less consequential decisions are easy, and many of them (like spam filters or autocomplete) have already been seamlessly integrated into daily life. Recent advances in AI have allowed for the possibility of non-routine decisions to be automated as well, but the “squishiness” of models and the difficulties they often have in providing up-to-date factual information mean that there is some risk in automating any non-routine task.
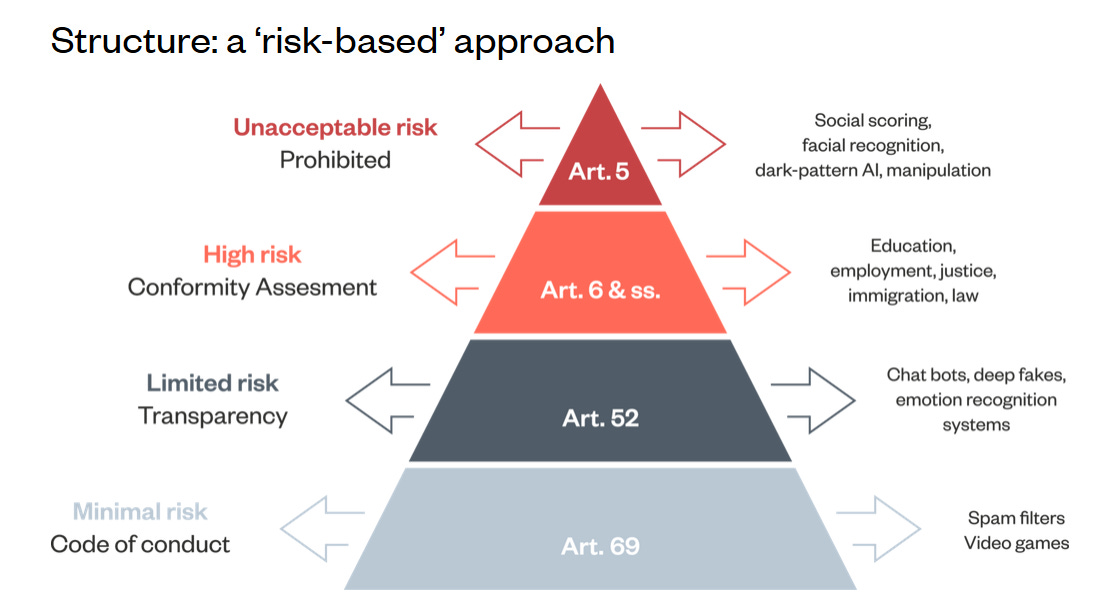
The line between routine and non-routine tasks can be blurry in highly consequential use cases like self-driving cars. If a self-driving car has training on how to handle 99.999% of situations, how does it handle the 0.001% of situations that are truly exceptional? It’s important to note that both of these axes are spectrums, and what seems non-routine today may become more routine later when more data is collected and the developer of the AI system is able to sufficiently assume liability for any harm that might be caused. Liability for the more consequential use cases naturally needs regulation to function, and the EU AI Act’s risk-based approach (in final negotiation as of October 2023) includes tiers of risk (limited, low, high, and unacceptable) that roughly correspond with the four categories of this automation matrix. However, it’s important to note that some tasks that could be routine but would be highly consequential if widely done by machines (like facial recognition and its dangers) might fall into the “Unacceptable risk” category.
Public opinion and trust, perceived benefits and risks
Regulation and public opinion ideally go hand-in-hand. How are public opinion, public trust, and social norms around emerging technology measured? How does the public perceive both benefits and risks from AI and robotics, and how much does that reflect or differ from the range of opinions expressed by experts?
Pew Research has a whole category of their research dedicated to tracking public opinion on AI. A poll they conducted in the summer of 2023 found that the American public tends to be more concerned that excited. Opinions differ elsewhere in the world though— public opinion across eastern Asia has historically been much more optimistic. Considering that there is more investment in AI in the US than anywhere else, does this imply we might see a shift in AI investment from west to east in the coming years? Curiously, a similar difference in attitudes between these two regions (exacerbated by a terrible accident in the year 2055) appears to be the premise of the movie The Creator.
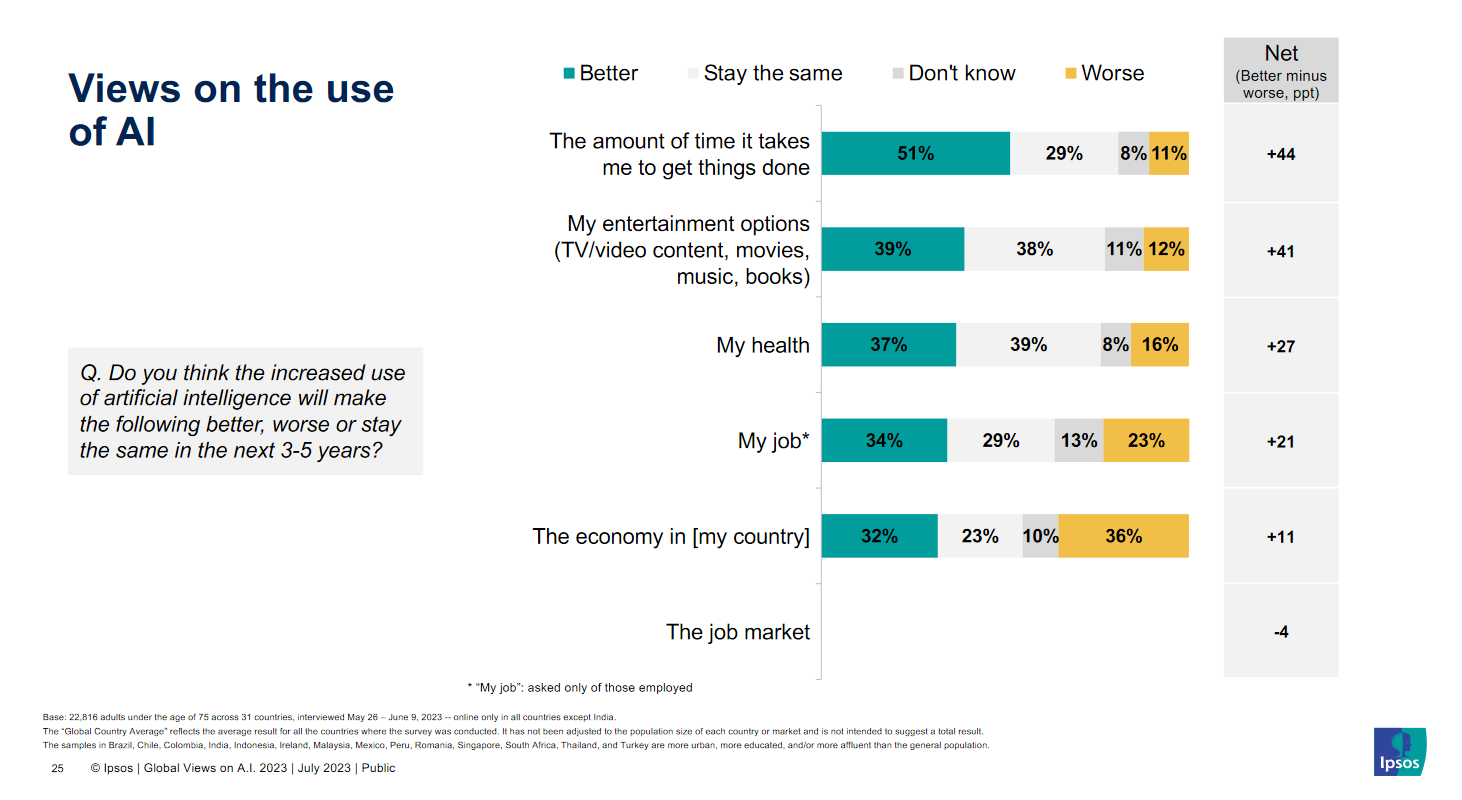
Of course, as this movie shows, public opinion about new technology can shift rapidly in response to current events. It is interesting to consider what benefits and risks people in different parts of the world are most excited and concerned about, and this Ipsos survey in the summer of 2023 asked just that. It found a big shift compared to 2021 toward agreement that products and services using artificial intelligence will profoundly change daily life in the next 3-5 years. It found an even bigger shift toward people agreeing that such products and services made them nervous.

In terms of aspects of AI that people were most optimistic about, saving time, improving entertainment options, and improving health featured high on the list.
Other improvements related to jobs and the economy were more controversial. A similar pattern to other global surveys held in that the US and other Western countries were more skeptical. India, southeast Asian countries, and Latin American countries were more optimistic, though the survey tended to oversample more online, wealthier individuals in these areas.
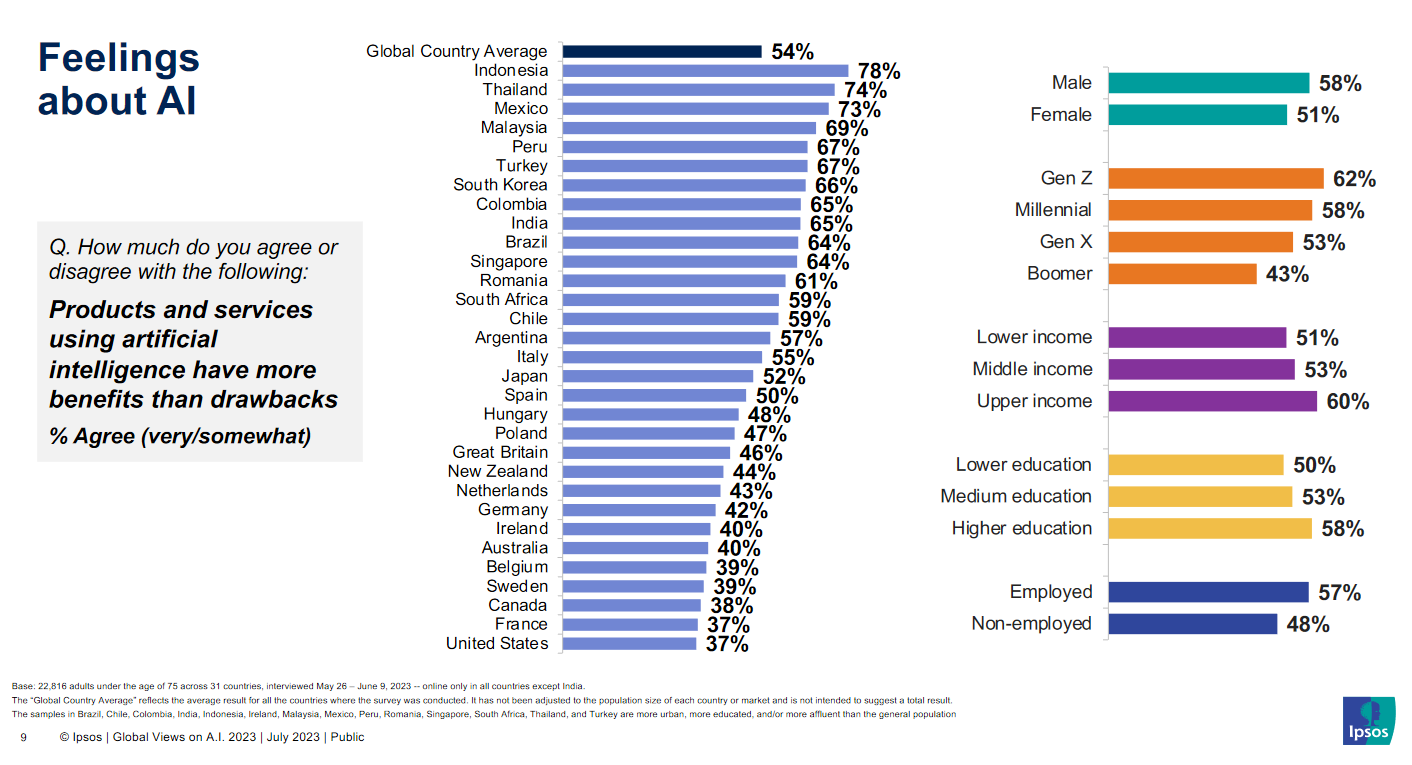
In considering the risks of AI, this survey mostly focused on the economy and the job market, but it did also ask questions about trust in AI companies to protect user privacy and not show bias. The patterns of optimism and skepticism in responses to these questions are similar.
The difficulty of weighing AI risks against each other
One thing the Ipsos survey did not ask is to have people rank their top concerns about AI. From the growing database of AI-related incidents to more theoretical concerns about AI posing an existential threat to humanity, considerations about what risks warrant the greatest share of our limited attention are hotly contested among the various factions of experts. But if measuring AI’s abilities and predicting when developments will occur is already difficult, assessing the scale of threats compared to when they might occur (short-term vs long-term) is even harder for an average person to assess.
In future pieces, I’d like to do some deeper dives into AI and robotics capabilities, including some more specific predictions that could help better contextualize a later exploration of the various risks. I haven’t yet seen a good data-driven piece that contextualizes the various threats in the way that I am envisioning, but will update this section if I do encounter something. In the meantime, Rohit Krishnan has published a few pieces that have helped me think about high-level taxonomies of AI risks, and the improbability of complete catastrophe. AIRS has proposed another more detailed taxonomy of risks, and Stanford’s annual HAI report also includes robust metrics of ethical considerations, representation in the field, and the risks that companies consider most important.
Keeping up with AI regulations
Among many other things, Stanford’s annual report also includes a detailed section about the regulation of AI. The one drawback is that news in AI moves fast, and while regulations move somewhat slower, there are more up-to-date, comprehensive sources of information elsewhere. While major changes in regulation are likely to be covered by major news outlets, what about changes in policy that fly under the radar?
Privacy-focused groups have us covered here. The IAPP provides periodic summaries of the state of regulation at the national and international level, while EPIC has coverage of U.S. state level regulations. If you’re specifically interested in regulations about how the liability of self-driving cars are assessed, this Wikipedia page is regularly updated across many jurisdictions. The only caveat is that these summaries aren’t easily filterable if you want to look at trends in a particular type of regulation across jurisdictions, though perhaps this is something that applications of AI might make easier? It’s interesting to imagine an AI assisting with the categorization of these regulations across various taxonomies in closer to real-time as regulations are negotiated and passed, though a matter as important as coverage of regulation would also likely continue to require human review before publication!
Wrapping it all up
So there you have it! You should now have a good mental model for these top 6 trends in AI and robotics. If you’ve made it through all of it, thank you! I hope my explanations help you connect whatever you might read day-to-day to the bigger picture. This analysis ended up being a lot longer than I’d originally anticipated when I first started writing it in July of 2023, and there were definitely some more examples and details I wanted to dive into, but cut for the sake of brevity.
If there was one variable I had to pick to study more, it would be accuracy and alignment. The future trajectory of this is the biggest unknown even among experts. Epoch AI, whose research I’ve cited extensively here, has come up with a sandbox for people to model when transformative, human-level AI might arrive. These variables in this sandbox roughly line up with the ones outlined in this piece, with the following clarifications:
The variables related to computing power and algorithmic progress line up just about exactly.
The investment related variables assume investment translates directly into model size.
There is no equivalent variable correlated with public opinion and regulation37.
Their “compute requirements” variables are the most abstract, but they correspond with accuracy and alignment and are explained more in their paper on the Direct Approach.
Epoch’s Direct Approach effectively hypothesizes that for every 6 orders of magnitude (OOM) that effective FLOP (model size + algorithmic improvement) is increased, the ability of AI also increases by an order of magnitude. But what does that mean in practice? It does NOT mean that an ability where AI is at 80% human level would be at 800% of human level, but rather that the context window is extended. In other words, a model that performs 10 times as well can generate an output that is 10x larger at a similar level of accuracy. So, if today’s state-of-the-art models can write human-level blog posts, this theory suggests that a 6 OOM increase in FLOP would put us at human-level scientific papers, and that length (the K-level) might be enough for AI to radically transform the economy and society. If we assume that hardware will grow by 1 OOM in 10 years, as will investment, and algorithmic improvements grow by an OOM every 2.5 years, that puts us at 6 OOMs of additional effective FLOP within a decade.
Of course, to say that state-of-the-art models can write a human-level blog post, or its equivalent in images or video isn’t necessarily true in all cases. This is where the “Human slowdown factor” comes in. You can think of a lower value here as AI’s performance at a task where a high level of accuracy is required. Maybe ChatGPT can produce average human-level writing for the length of a blog post for an average task, but would struggle to achieve a more exacting level of accuracy for anything longer than a tweet in other domains.
As helpful as this framework is for thinking about these concepts at a high level, the assumption that accuracy will continue to improve at the same rates per unit of computation as has previously been observed might not hold to be true, or may only be true for some abilities but not others. Alternatively, there could be further surprises ahead— perhaps some new technique, or a critical level of quality data unlocks abilities not previously observed. This is yet another argument for a more robust and transparent method of tracking AI capabilities.
The early 2020s have been full of surprises in terms of AI. But amidst the excitement, there are also some signals to be cautious about. It might be difficult to continue scaling models as quickly as was done in 2017-2023. If large context windows are important for more AI functions, what happens if their performance continues to be less than advertised? If there is a hype cycle with every new technology, is AI really that different?
If the real world continues to be messier than models suggest, I wouldn’t be surprised if we find ourselves in a “trough of disillusionment” at some point in the middle of the 2020s. In spite of this, I think the multimodality of AI and robotics technology has tremendous potential. I am optimistic we will see medicine improved and drudgery reduced. At the same time, I think the likely future path of automation means that jobs remaining for humans may be ones that require more intensity of judgement. Alongside this, there is a concerning trend towards more surveillance, both in the workplace and elsewhere. We will need to be vigilant to ensure gains from new technology are distributed in a way that benefits collective well-being. The impact of social media on mental health and politics is a cautionary tale. A question we should ask ourselves more, as individuals, as people interested in technology, and as participants in the public sphere: how can we spend more time doing what we love? How can we make this dream possible for the greatest number of people?
Acknowledgements
Writing this piece wouldn’t have been possible without the many experts out there who have generously shared their insights freely and publicly. I’ve learned a lot from them and I hope you can too. I’ve cited these folks extensively, but I would like to give another shoutout to:
The Epoch AI team (Jaime Sevilla, Tamay Besiroglu, Matthew Barnett among others) for their detailed analysis of high-level trends.
Dylan Patel’s SemiAnalysis for his team’s deep insights into the trends affecting hardware manufacturers.
Timothy B Lee’s Understanding AI for his deep-but-appoachable analysis of a wide range of AI topics that have significant economic impact.
Ethan Mollick’s One Useful Thing for a newsletter that lives up to its name and more.
Maggie Appleton’s Digital Garden for inspiring ideas about the design of AI.
Rex Woodbury’s Digital Native for his charts that capture how the world is changing
Sebastian Raschka’s Ahead of AI for the frequently summaries of the latest important papers in the field.
Charlie Guo’s Artificial Ignorance for the easily digestable explainers of important news in AI.
Stanford’s Human-Centered Artificial Intelligence program, for their extremely informative Annual Index Report, among their many other research initiatives.
The Metaculus community, whose forecasters appear to be more accurate than others, at least as of early 2023.
There is an incredible list of the most common GPUs used for machine learning applications in this Google Sheet here, and it is updated live!
Forecasters on Metaculus predict the first zettascale machine (~1,000 more powerful than 2022’s fastest supercomputer) to appear between 2032 and 2043.
Metaculus forecasts for the speed of the fastest supercomputer in the year 2122 are simply staggering!
On the other end of the scale, there is a fun visual tool here that allows you to imagine each individual node of knowledge as a star in a galaxy.
As of time of writing in October 2023.
Important levels of precision to know are as follows:
Top 500 supercomputer FLOP/s has historically been measured based on 64-bit floating point arithmetic as per the Linpack benchmark.
However, the above chart suggesting the limits to processing power improvements (from this Epoch AI report) references FLOP/s as “single-precision” (32-bit) performance.
The computation typically reported for LLM training in 2023 is measured in FP16 Tensor Core, which allows for further selective reductions in fidelity and greater amounts of FLOP per unit of processing power. This NVIDIA product spec sheet for the A100 (25,000 of these are rumored to have trained GPT-4) has a good illustration how FLOP/s varies at each level of fidelity.
Training LLMs using even shorter float numbers (such as 8-bit and 4-bit) is an active area of research in 2023.
This market measures model size in petaFLOP-days. One petaFLOP-day = 86.4 exaFLOP (8.64e19). So, a million petaFLOP-days = 8.64e25, or about 4x the size of GPT-4.
Another excellent resource from the Epoch AI team, similar to their ML hardware dataset cited above, is their list of notable ML systems, including important data about each. It is also updated live!
Many AI papers reference a loss function. This may in many cases be correlated with the performance of a model, but it is a separate concept, and there are also different types of loss functions.
As of writing this, the best performing model was assessed against this benchmark in November 2022. So, it’s certainly possible that if a more powerful model were tested, it would exceed the threshold shown in the chart.
Midjourney is widely considered to be the best tool for image generation but requires a paid plan. Open-source models like the ones available at dreamstudio.ai and clipdrop.co have been catching up quick though!
One interesting benchmark to follow from Papers with Code is this one that tracks models’ adversarial robustness— in this case, tracking how well a model can identify an image when different sorts of noise or other corruptions are applied.
Context windows in 2023 are likely too small for such a capable system to exist. The limited ability of AI to learn continuously and perform tasks of this complexity have reassured some researchers about the risks of a highly agentic machine intelligence.
The exercise of connecting technical evaluations of AI with O*NET’s list of knowledge, skills, and abilities (KSAs) will undoubtedly reveal some gaps in the existing framework, and shine a light on previously underappreciated skills. For example, commonsense reasoning is an area where AI still scores below human ability, but where does it fit in with the existing O*NET categories of reasoning skills, which currently only include inductive and deductive reasoning, but don’t fully capture the subtleties of causal, abductive and monotonic vs non-monotonic reasoning?
If you think there is a way I could help move something like this forward, please get in touch with me at eth [at] 2120insights.com!
Some argue that transformer architecture may have fundamental limitations, particularly when it comes to doing math, clearly explaining its reasoning, or fully understanding causality. If performance in these tasks hits a wall even after significant investment, there will be a tremendous amount of incentive to develop something new. Such an innovation could be developed in secret and come as a surprise.
In contrast, when an article mentions “zero-shot generalization to novel concepts and tasks”, this means that a model has learned to do something without any specific examples in its training data. These are often referred to as “emergent abilities”. Some argue that many emergent abilities arose in 2022 when AI models reached a certain size while others argue that these claimed abilities have only arisen due to differences in measurement that are biased against smaller models.
A good summary of the specialized lines of work in medicine, and how AI measures up in each area can be found here. While Google’s MedPaLM was close to human performance in generating radiology reports, ChatGPT struggled the most with differential diagnosis.
Another prompting strategy to make an AI response sound more rich and less general has been termed “chain of density”, explained in the image below. You can try out this prompt yourself by following the link here. I wish I had come across this sooner!

An idea I have related to this: knowing how good generative AI is at containing a wealth of information, I’d be interested in having an AI personal assistant that reminds me if I’m reinventing the wheel, and makes suggestions about who I might be able to learn more from.
Since these figures are coming from the company that makes the software, I’d give the lower estimates more credence :)
However, this article about how AI is poised to change software engineering and product management was an insightful read. It makes me think that the future of software development isn’t the production of software being fully automated, but rather software becoming cheaper to develop and solving problems that previous technology and costs weren’t able to crack.
In doing research on these, I came across a site that offers deep discounts on some of these paid browser extensions, including lifetime subscriptions for the price of just a few months!
To give you a sneak peak, here’s a distribution chart of the BLS’ forecasted annual growth rate for all occupations from 2022 to 2032, at the same scale as the distribution charts I published in my analysis of historic occupational change:
You’ll notice this projection is much more conservative than any historic change on record, especially for a decade where the nature of work could change so much. I plan to propose some areas where the BLS could improve their projections.
This chart was generated entirely by ChatGPT’s Advanced Data Analysis tool, though the complexity of the ask meant it did take me a couple of hours to get it right. This is still somewhat faster than what I would have otherwise done in Google sheets. The biggest value add I think will be helping me publish a series of interactive charts like this one, involving D3.js code that I am not familiar with— a very personal example for me of how AI tools can help beginners level up their skills more than experts.
There have been quite a few stories about the hidden labor of data annotators who are often tasked with labeling datasets as well as training AIs through reinforcement learning from human feedback (RLHF). Data about these annotators can be hard to come by due to the work being spread out across so many countries, but scholars at the University of Oxford determined there were 163 million people around the world registered to do this work in 2021, 19 million of whom have been paid and 5 million of whom have earned at least $1,000.
The data annotation industry is closely related to the content moderation industry. Workers in both industries are frequently exposed to disturbing content, and both of these industries are expected to grow significantly over the coming decade, from $13 billion to $40 billion per year between 2022 and 2032 for content moderation, and a rapid rise from $1.8 billion to $25 billion between those same years for data annotation.
I was surprised to see so much growth in the forecast for the content moderation market given that one of the benefits of AI may be to automate moderation to some degree, particularly of the most graphic content (though annotators who create the data for these systems would still be exposed to it, at least initially). It would be good to see some more transparency on progress here going forward, in hopes that we might solve at least one of the problems brought on by social media.
Stanford’s HAI Report also tracks how many North American CS grads there are each year— only about 50,000 per year for all levels combined!
Except for companies with more than 700 million daily active users.
This assumes that half of the revenue of the generative AI market continues to come from the US. Realistically it may be somewhat less.
Based on a $432 stock price divided by $10.80 (Q2 2023 earnings of $2.70/share x 4)
As a thought experiment, consider that forecasters on Metaculus estimate that the largest training run in 2032 will be somewhere between 20x and 1,200x the size of GPT-4. If we might expect 1-1.5 orders of magnitude in improvements in the price-performance of GPUs by then, that means a range of scenarios of GPU demand, from roughly no growth to 100 times as much investment in GPUs (at least for a single training run). Over 9 years, that’s anywhere from zero growth to 67% annually! Taking the average of these implies 33% growth, but with a standard deviation of 40%. This is much wider than the 15% standard deviation of the S&P 500 in any given year and so could be considered quite speculative. The question of how much overall demand for GPUs scales with the size of the largest clusters and models adds yet another layer of uncertainty.
Another way of visualizing the potential volatility: there is another Metaculus market that predicts the odds that NVIDIA’s price will fall below $250 before 2025.
The US Census does track Robotic Capital Expenditures for Selected Industries on an annual basis here. The $5.6 billion invested in US industrial robots adds up to about 2.1% of the $267 billion invested that year in industrial equipment overall. A more detailed breakdown of industrial equipment expenses can be found here.
With a wide range depending on its function and where it was made.
Chinese companies are most concentrated in the industrial sector (including acquisitions of specialized companies like KUKA), but are also rapidly expanding into the consumer service robot market. Ecovacs Robotics surpassed Roomba-maker iRobot based on its lower prices and the latter’s struggle with the chips shortage and complicated acquisition by Amazon.
The referenced report includes consumer service robots, whose estimate I break out here because of the very different growth rates.
I respect the research that Tamay Besiroglu has done here, and have cited his work on algorithmic improvements and historic computing price-performance trends elsewhere. However, his prediction that 30% world GDP growth in a single year before 2100 is as likely as not strikes me as wildly optimistic.
His argument hinges on a rapid scaling of the digital workforce, which is theoretically possible, but as I explored in my own wildly optimistic prediction of when we’ll see a 15-hour workweek, it seems unlikely that we would automate much more than 3.5% of all jobs in any given year. Even at that rate, it’s difficult to realize 30% GDP growth, unless the new AI workforce allows for production nearly 10 times greater than its automation potential in a single year. And even if a 30% improvement in production within a year is plausible in a field like manufacturing, there might be other industries where a 30% increase in production (like agriculture) might go to waste. In other fields like healthcare, AI’s value add might be in reduced costs rather than increased production, which would make it difficult to realize 30% GDP growth in this area even if labor productivity were to increase by that amount.
Dietrich Vollrath gives a more detailed breakdown of why such high rates of growth are an impossibility here, and I hope to write a more detailed take on this in a future piece.
One other aspect to consider: even if the technology of AI overpromises and underdelivers (including the risk of over-investment), it might still force a valuable rethinking of processes. For example, 59% of executives in a June 2023 survey indicated that their data was either somewhat or completely siloed. Improvements here could still result in significant efficiencies even with existing technology.
These figures are also a good reminder that just because an industry best practice exists doesn’t mean that all companies will immediately adopt it. This is another point in favor of steady growth rather than the theoretical forecasts of an explosion.
Investment in cybersecurity applications of AI is growing rapidly as of 2022, and comprises over 3% of all cybersecurity spend. Even so, McKinsey estimates that global cybersecurity spend in 2021 was only about 10% or less of the total potentially addressable market. This puts the total around 0.15% of global GDP, with an addressable market of 1.5-2% of GDP.
US cybersecurity spending is currently well ahead of the world average. Comprising nearly 10% of IT spend in 2022 (itself over 4% of US GDP), current US spending is about 0.4% of GDP. About 0.67% of the US workforce is employed in cybersecurity in 2023, and if all open cybersecurity jobs were filled, employment in the field would be 69% higher. Curiously, the ratio of open jobs to filled ones is almost half what it was in the early 2010s, suggesting that demand isn’t as high as before. McKinsey’s estimate may be too high, though it’s also likely that companies aren’t looking to spend as much as they should.
On the other hand, we have the scale of the threat. The FBI’s IC3 estimated $10.3 billion in losses in 2022, a whopping 50% increase over the previous year. It’s important to note that the DOJ estimates that only 1 in 7 cybercrimes is reported, so total losses could be $50 billion or more, or roughly 0.2% of US GDP. This could be even higher if the hidden costs of cyberattacks such as downtime are considered— global estimates of 1% of GDP lost to cybercrime include these damages. Even the lower direct loss figure would represent about 2-3% of the total direct (transfer) losses of all crime in the US which was estimated in 2021 to be about $1.8 trillion. It’s not hard to imagine that with AI assistance, scammers and cybercriminals could set another significant record in 2023.
Another way to interpret McKinsey’s estimate of the addressable market (other than a pitch for their services) is to imagine that’s the demand for cybersecurity services there could be if AI significantly increased the threat. If addressed within a year, that would be nearly 2% global GDP growth, but not the happy kind, and likely coming at the expense of other activities.
To be fair, this is hard to model, but such a variable could be well-suited for a high-level economic model that looks at regulation’s likely impact on different industries.